
https://medium.com/byte-sized-ai/llm-inference-optimizations-2-chunked-prefill-764407b3a67a

·
Published in
·
8 min read
·
Aug 28, 2024
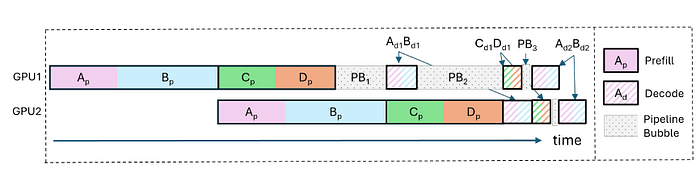
Large Language Model (LLM) inference involves two key phases: the prefill phase, which processes the input prompt, and the decode phase, which generates output tokens one at a time in an autoregressive manner. While the prefill phase efficiently utilizes GPU resources, especially at small batch sizes, the decode phase suffers from low GPU utilization due to its token-by-token processing. Additionally, the differing durations of the prefill and decode phases can cause imbalances across micro-batches in pipeline parallelism, leading to inefficiencies and pipeline bubbles. The figure below illustrates how conventional ***continuous batching [3]*** suffers from pipeline bubbles due to workload imbalance between prefill and decode requests.
2 GPUs in pipeline parallelism setting handle 4 requests (A,B,C,D) using continuous batching [1]
To address the aforementioned inefficiencies of conventional continuous batching, SARATHI utilizes “chunked-prefills,” which divide a prefill request into equal-sized chunks, along with “decode-maximal batching,” which forms a batch by combining one prefill chunk with additional decode requests. During inference, the prefill chunk fully utilizes GPU resources, while the decode requests piggyback, significantly reducing computational costs compared to processing decodes independently. This method enables the creation of multiple decode-maximal batches from a single prefill request, optimizing the handling of decode requests. Additionally, the consistent compute load of these batches mitigates imbalances across micro-batches, effectively reducing pipeline inefficiencies.