
https://medium.com/byte-sized-ai/inference-optimizations-1-continuous-batching-03408c673098

·
Published in
·
6 min read
·
Aug 24, 2024
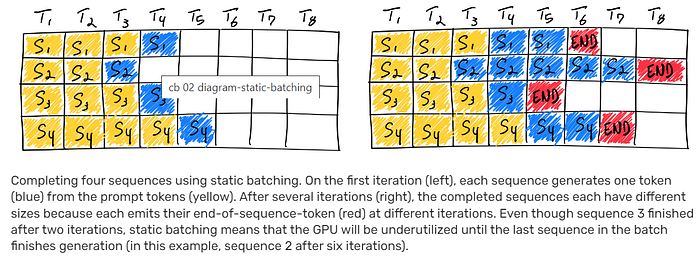
Batching for large language models (LLMs) is challenging due to the iterative nature of their inference. The difficulty arises because requests within a batch can complete at different times, making it complex to release their resources and incorporate new requests that are at varying stages of completion. As a result, the GPU may be underutilized, especially when the generation lengths of sequences in a batch vary significantly from the longest sequence. This inefficiency is depicted in the figure below by the white squares following the end-of-sequence tokens for sequences 1, 3, and 4, indicating unused GPU resources.
figure from [2]
ORCA, which introduces the concept of Continuous Batching, features iteration-level scheduling and selective batching to effectively address the challenges associated with batching in large language models.