
https://medium.com/@plienhar/llm-inference-series-2-the-two-phase-process-behind-llms-responses-1ff1ff021cd5
Top highlight
·
4 min read
·
Dec 22, 2023
This relatively easier post will be the opportunity to warm up by getting back to the basics of the Transformer architecture and text generation using Transformer-based decoders. Most importantly, I will establish the vocabulary I will use throughout the series. I highlight in bold the terms I personally favor. You will in particular learn about the two phases of text generation: the initiation phase and the generation (or decoding) phase.
First, a little Transformer refresher. For simplicity, let’s assume that we process a single sequence at a time (i.e. batch size is 1). In the figure below I pictured the main layers of a vanilla Transformer-based decoder (Figure 1) used to generate an output token from a sequence of input tokens.
Figure 1 —Outline of a Transformer decoder model
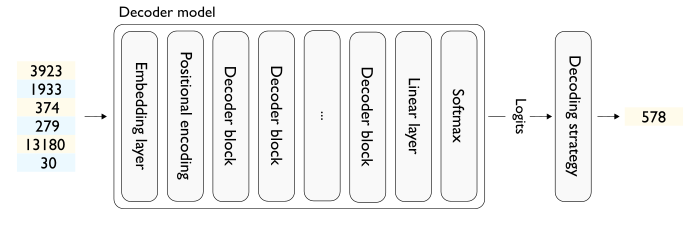
Notice that the decoder itself does not output tokens but logits (as many as the vocabulary size). By the way, the last layer outputting the logits is often called the language model head or LM head. Deriving the token from the logits is the job of a heuristic called (token) search strategy, generation strategy or decoding strategy. Common decoding strategies include:
For the sake of simplicity, we will assume the decoding strategy to be part of the model (Figure 2). This mental model is actually useful in the context of LLM serving solutions where such entities that take a sequence of tokens as input and return a corresponding output token are usually called an execution engine or an inference engine.