
https://medium.com/@plienhar/llm-inference-series-4-kv-caching-a-deeper-look-4ba9a77746c8
Top highlight
·
18 min read
·
Jan 15, 2024
In the previous post, we introduced KV caching, a common optimization of the inference process of LLMs that make compute requirements of the (self-)attention mechanism to scale linearly rather than quadratically in the total sequence length (prompt + generated completions).
More concretely, KV caching consists to spare the recomputation of key and value tensors of past tokens at each generation step by storing (”caching”) these tensors in GPU memory as they get computed along the generation process.
KV caching is a compromise: we trade memory against compute. In this post, we will see how big the KV cache can grow, what challenges it creates and what are the most common strategies used to tackle them.
This is quite simple: for each token of each sequence in the batch, we need to store two vector tensors (one key tensor and one value tensor) of size d_head for each attention head of each attention layer. The space required by each tensor parameter depends on the precision: 4 bytes/parameter in full-precision (FP32), 2 bytes/parameter in half-precision (BF16, FP16), 1 byte/parameter for 8-bit data types (INT8, FP8), etc.
Let be b the batch size, t the total sequence length (prompt + completion), n_layers the number of decoder blocks / attention layers, n_heads the number of attention heads per attention layer, d_head the hidden dimension of the attention layer, p_a the precision. The per-token memory consumption (in bytes) of the KV cache of a multi-head attention (MHA) model is:
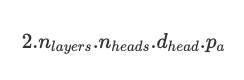
Notice: We remind that in MHA models, n_heads.d_head=d_model but we won’t use it to simplify the formula above.
The total size of the KV cache (in bytes) is therefore: